
OpenAI Codex桌面版深夜突袭!一人指挥Agent军团,程序员彻底告别996
OpenAI Codex桌面版深夜突袭!一人指挥Agent军团,程序员彻底告别996太带劲了!抢先Claude 5,OpenAI深夜祭出了一个编码杀器——Codex。它可以让一人指挥多Agent并行协作,自带Skills,编码从此进入自动化时代。
来自主题: AI资讯
12124 点击 2026-02-03 10:03
 搜索
搜索
太带劲了!抢先Claude 5,OpenAI深夜祭出了一个编码杀器——Codex。它可以让一人指挥多Agent并行协作,自带Skills,编码从此进入自动化时代。
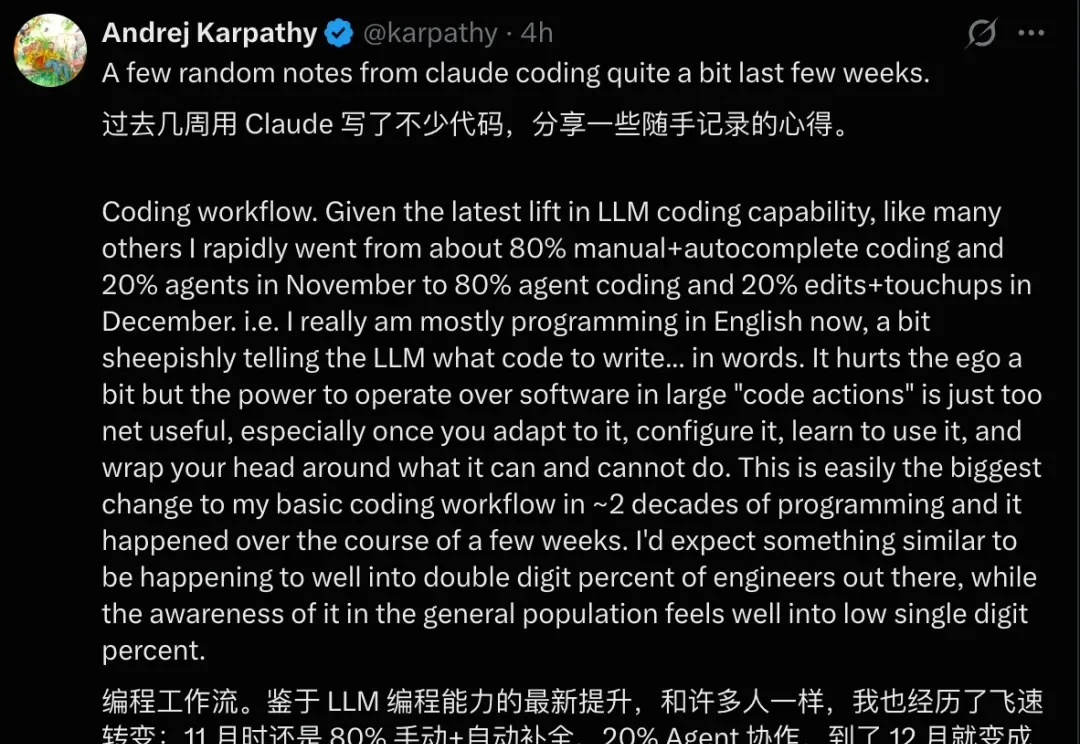
最近,OpenAI 创始成员 Andrej Karpathy 在推特上分享了他使用 Claude 进行数周高强度编程后的感受。

OpenAI 11位联创只剩3人,Ilya出走创办SSI,John Schulman跳槽Anthropic……而Anthropic的7位创始人至今无人离队。稳定,才是最大的竞争力。
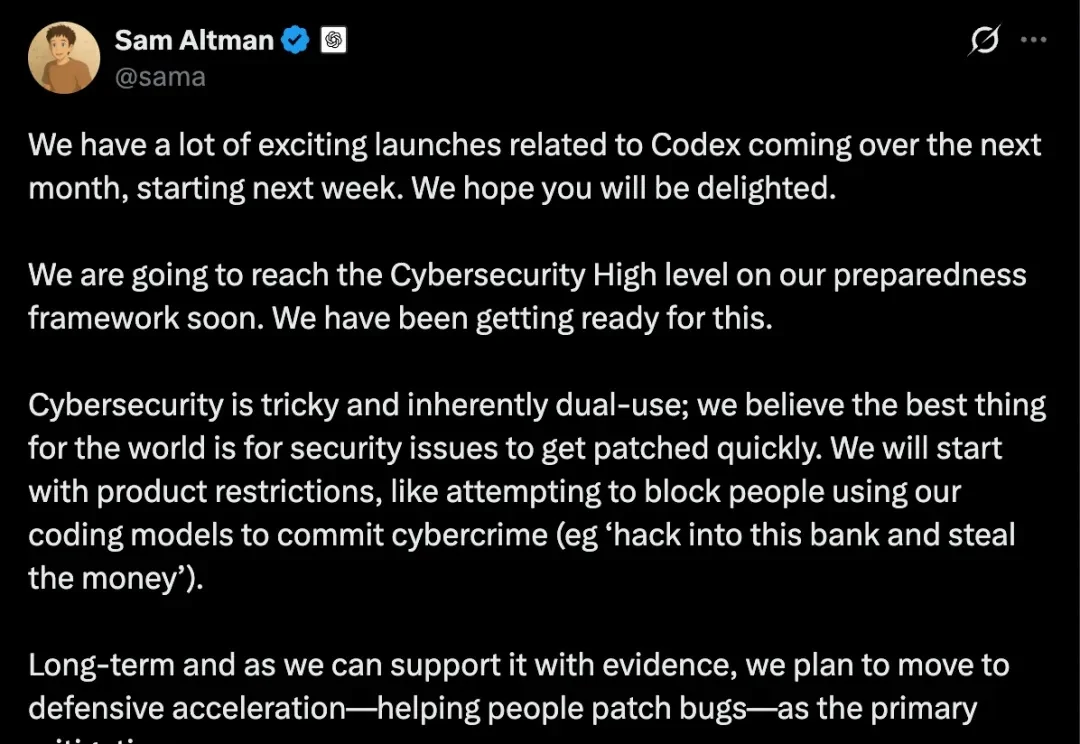
ChatGPT 最近明显又有点焦虑。

Anthropic 又一次证明,「超级底层」,才是 AI 成功的关键。
“DeepSeek-V3是在Mistral提出的架构上构建的。”
过去两年,大模型的推理能力出现了一次明显的跃迁。在数学、逻辑、多步规划等复杂任务上,推理模型如 OpenAI 的 o 系列、DeepSeek-R1、QwQ-32B,开始稳定拉开与传统指令微调模型的差距。直观来看,它们似乎只是思考得更久了:更长的 Chain-of-Thought、更高的 test-time compute,成为最常被引用的解释。
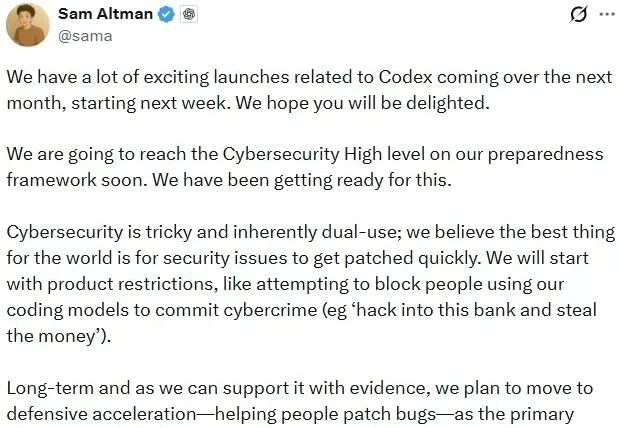
进入到 2026 年,OpenAI 在关注消费级产品(如 ChatGPT、社交应用)之外,开始将一部分重心转向企业级市场。
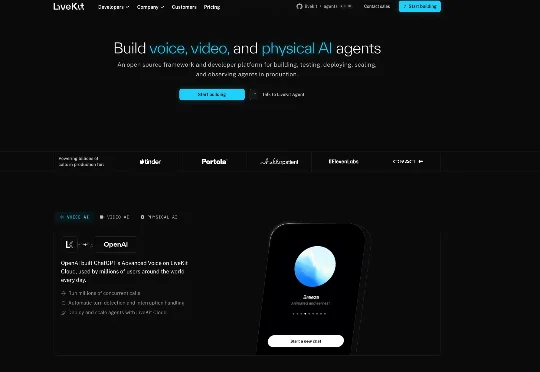
提供软件支撑OpenAI 等公司语音、视频及实体 AI 模型的初创企业 LiveKit,在一轮融资中筹集了 1 亿美元,公司估值达 10 亿美元。LiveKit 的软件和网络运行着利用语音、视频以及所谓物理 AI(应用于机器人技术等任务)的人工智能模型。

有没有发现,大厂都在布局自己的AI硬件产品。 在达沃斯现场,OpenAI 的全球事务官克里斯·莱恩透露了一个最新消息,OpenAI 正在按计划推进,准备在 2026 年下半年推出首款 AI 硬件设备。